基于协同过滤的商品推荐
问题背景
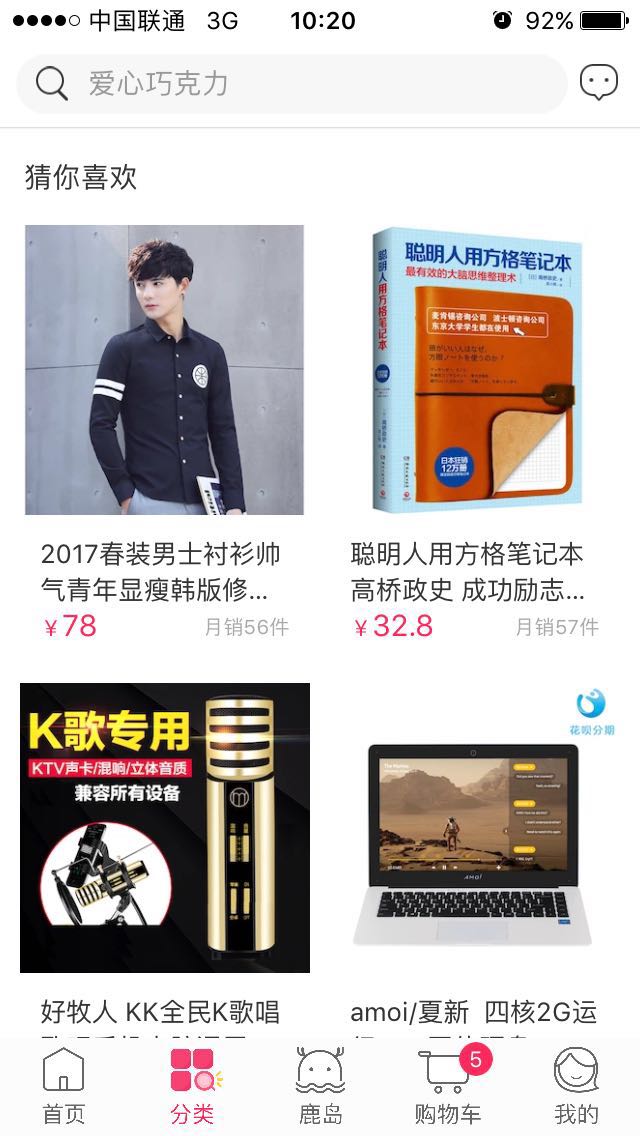
用户逛电商APP时,经常会有 猜你喜欢 的场景,如下图某电商APP的猜你喜欢场景,猜测用户可能喜欢的商品,并按照喜欢的强弱程度给出Top N个商品。那么,如何猜测用户喜欢的商品呢?
问题分析
用户在逛电商APP时,会浏览(PV)很多商品,看到自己喜欢的商品,一般会有点击(CLICK)、收藏(FAV)、加购(CART)和下单(ORDER)行为。从CLICK到ORDER行为隐性的反馈了用户的喜好,当用户购买过商品后,会对商品进行评价(COMMENT),通过打分或者评价内容可以显性的表达用户的喜好。
本文基于协同过滤算法,通过分析用户历史点击(CLICK)、收藏(FAV)、加购(CART)和下单(ORDER)行为,预测用户喜欢的商品,推荐给用户。
协同过滤
协同过滤算法分为以下两类
- 基于用户的协同过滤算法(user-based collaboratIve filtering)
- 基于物品的协同过滤算法(item-based collaborative filtering)
简单的说就是:人以类聚,物以群分。这里主要介绍基于物品的协同过滤算法。
基于物品的协同过滤算法,用于计算商品之间的相似度,即对商品 $a$ 有过行为的用户还对哪些商品有过行为。这里的行为可以是CLICK、FAV、CART和ORDER,代表用户对商品的态度和偏好。如果对商品 $a$ 有过行为的用户中大部分还对商品 $b$ 有过行为,则认为商品 $a$ 和商品 $b$ 比较相似。
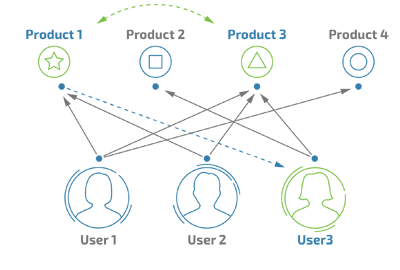
以商品 $a$ 和商品 $b$ 为例,如何计算商品之间的相似度呢,一般有以下几种算法:
Jaccard相似系数
Jaccard 相似系数是衡量两个集合相似度的一种指标,公式如下:
$$sim_{Jaccard}(a, b) = \frac{|A \cap B|}{|A \cup B|}.$$
其中,$A$ 代表对商品 $a$ 有过行为的用户集合,$B$ 代表对商品 $b$ 有过行为的用户集合。如果对商品 $a$ 和商品 $b$ 有过行为的用户中,对两个商品都有行为的用户数量越多,则代表两个商品越相似。
余弦相似系数
余弦相似系数,也称余弦距离或余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。公式如下:
$$sim_{cosine}(a, b) = \frac{\vec{A}\cdot\vec{B}}{\Vert A \Vert \cdot \Vert B \Vert}.$$
当用于计算两个商品相似度时,上面公式中 $A$ 表示对商品 $a$ 有过行为的每一个用户对商品 $a$ 的评分,$B$ 表示对商品 $b$ 有过行为的每一个用户对商品 $b$ 的评分。
例如分别有 $n$ 个用户对商品 $a$ 有过行为,有 $m$ 个用户对商品 $b$ 有过行为,评分分别为
- $(A_{1}, A_{2}, \cdots, A_{n})$
- $(B_{1}, B_{2}, \cdots, B_{m})$
两个商品都有过行为的用户个数为 $k$ 个,则商品 $a$ 和 $b$ 的余弦相似度为:
$$sim_{cosine}(a, b) = \frac{\sum_{i=1}^{k}A_{i}\cdot B_{i}}{\sqrt{A_{1}^{2}+A_{2}^{2}+\cdots+A_{n}^{2}}\cdot \sqrt{B_{1}^{2}+B_{2}^{2}+\cdots+B_{m}^{2}}}.$$
皮尔逊相关系数
皮尔逊相关系数,范围在 $[-1, 1]$ 之间,公式如下
$$\begin{eqnarray}
\rho_{a,b} & = & \frac{cov(A,B)}{\sigma_{A}\cdot\sigma_{B}} \\
{} & = & \frac{E((A-\mu_{A})\cdot(B-\mu_{B}))}{\sigma_{X}\cdot\sigma_{B}} \\
{} & = & \frac{E(A\cdot B)-E(A)\cdot E(B)}{\sqrt{E(A^{2})-E^{2}(A)}\cdot\sqrt{E(B^{2})-E^{2}(B)}}.
\end{eqnarray}$$
欧几里德距离
欧几里德距离通过计算两个商品在散点图中的距离来判断不同的商品是否相似。公式如下
$$sim_{Euclid}(a, b) = \sqrt{(A_{1}-B_{1})^{2}+(A_{2}-B_{2})^{2}+\cdots+(A_{n}-B_{n})^{2}}.$$
上面公式中,商品 $a$ 和 商品 $b$ 分别有 $n$ 个用户有评分。如果有用户对商品 $a$ 或者商品 $b$ 没有行为,则可假设评分为零。
个性化推荐
对用户进行个性化推荐,寻找用户喜欢的商品,分为两步
- 基于所有用户对商品的历史行为,计算出每个商品的相似商品;
- 对每个用户有过直接行为的商品,寻找出相似的商品推荐给用户。
寻找相似商品
寻找每个商品相似的商品,基于上述物品的协同过滤算法。考虑用户 $U$ 对商品 $I$ 有点击(CLICK)、收藏(FAV)、加购(CART)或下单(ORDER)行为,每种行为代表了用户对商品的态度和偏好,假设对这4种行为的偏好以评分的形式进行量化,形式化如下
$score=(s_{click}, s_{fav}, s_{cart}, s_{order}).$
如果用户 $U$ 对商品有 $I$ 点击(CLICK)、收藏(FAV)、加购(CART)或下单(ORDER)行为,则用户 $U$ 对商品 $I$ 评分可定义如下:
$score(U, I) = \sum_{b \in \{click, fav, cart, order\}}(w_{b}\cdot s_{b}).$
其中,$w_{b}$ 代表4种行为的权重,定义如下
$$
w_{b}=\begin{cases}
1 & \text{count(b)>0},\\
0 & \text{count(b)=0}.
\end{cases}
$$
$count(b)$,$b \in \{click, fav, cart, order\}$,分别代表4种行为的次数。
假如商品 $a$ 和 商品 $b$ 有过行为的用户数分别为 $n$ 和 $m$ 个,评分分别为
- $((I_{a}, U_{a, 1}, score(I_{a}, U_{a, 1}), (I_{a}, U_{a, 2}, score(I_{a}, U_{a, 2}),\cdots, (I_{a}, U_{a, n}, score(I_{a}, U_{a, n}))$
- $((I_{b}, U_{b, 1}, score(I_{b}, U_{b, 1}), (I_{b}, U_{b, 2}, score(I_{b}, U_{b, 2}),\cdots, (I_{b}, U_{b, m}, score(I_{b}, U_{b, m}))$
且对商品 $a$ 和 商品 $b$ 共同有过行为的用户数为 $K$ 个,则余弦相似度为
$$\begin{eqnarray}
sim_{cosine}(a, b) = \frac{\sum_{k=1}^{K}(score(I_{a}, U_{a,k})\cdot score(I_{b}, U_{b,k}))}{\sqrt{\sum_{i=1}^{n}score^{2}(I_{a}, U_{a, i})}\cdot\sqrt{\sum_{j=1}^{m}score^{2}(I_{b}, U_{b, j})}}.
\end{eqnarray}$$
根据公式 (4) 就可以计算出任意两个商品之间的相似度,也就可以寻找出一个商品的相似商品了。
寻找用户喜欢商品
用户在逛电商APP时,会浏览(PV)很多商品,看到自己喜欢的商品,一般会有点击(CLICK)、收藏(FAV)、加购(CART)和下单(ORDER)行为。寻找用户喜欢的商品,即可以计算用户直接有过行为的商品的相似商品。方法如下图
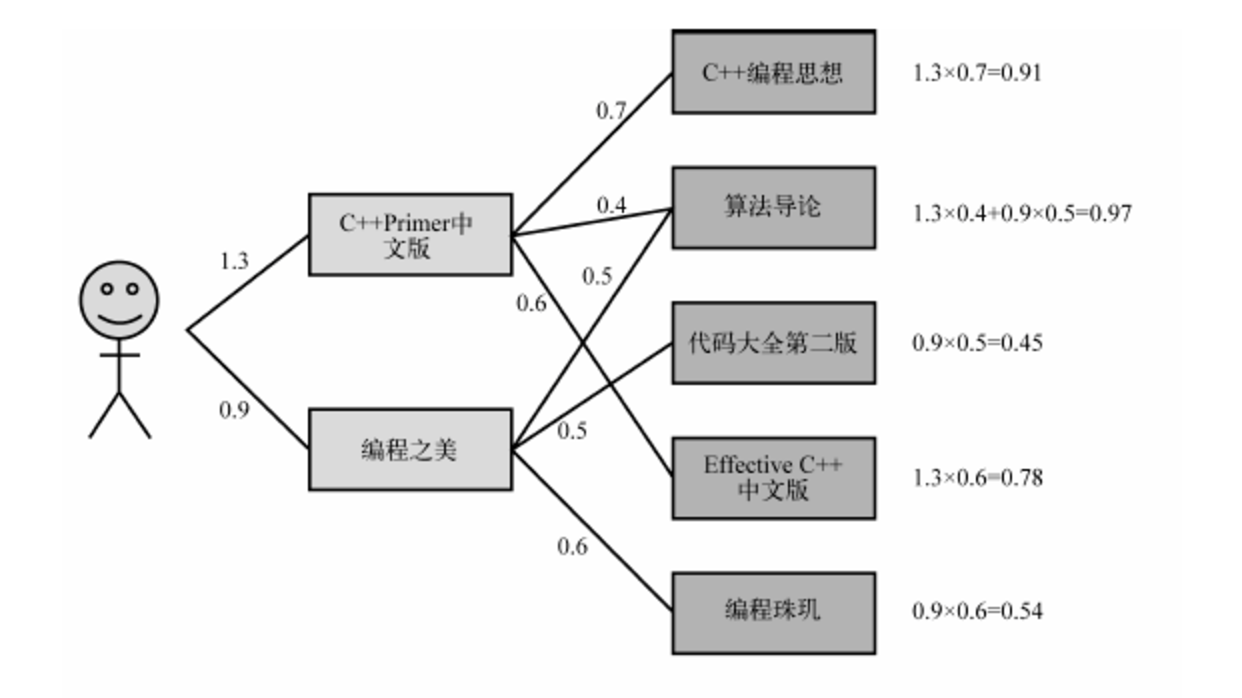
用户直接有过行为的商品为 C++Primer中文版本 和 编程之美,而与 C++Primer中文版本 相似的商品有 C++编程思想 、算法导论 和 Effective C++中文版;与 编程之美 相似的商品有 算法导论 、代码大全第二版 和 编程珠玑。要计算用户对 算法导论 的喜欢程度,即用户对 C++Primer中文版本 的评分,与 算法导论 和 C++Primer中文版本 的相似度的乘积,再加上用户对 编程之美 的评分,与 算法导论 和 编程之美 的相似度的乘积,两者的和即是用户对 算法导论 的感兴趣程度。形式化寻找用户喜欢商品的过程如下
用户 $U$ 直接有过行为的商品集合为
- $(I_{1}, I_{2}, \cdots, I_{n})$
这些商品中,每个商品 $I_{i}$,$1\le i \le n$,的相似商品集合为
- $(I_{i,1}, I_{i, 2}, \cdots, I_{i, m})$
不同的商品 $I_{i}$,相似商品的个数 $m$ 可能不同。计算用户 $U$ 对指定一个商品 $I$ 的喜好程度,公式如下
$$\begin{eqnarray}
like(U, I)=\sum_{i=1}^{n}(score(I_{i}, U)\cdot sim_{cosine}(I_{i}, I)).
\end{eqnarray}$$
根据公式 (5) 可以计算出感兴趣的商品集合,然后按照喜好程度选择Top N个商品就可以推荐给用户。
算法优化
基于业务背景优化
活跃用户
在计算商品相似度时,基于商品的协同过滤算法使用了用户对商品的行为,用户的行为对商品的相似度产生了贡献,那么是不是每个用户的贡献都相同呢?这里使用 项亮 在 《推荐系统实践》中例子进行分析。
假设有这么一个用户,他是开书店的,并且买了当当网上80%的书准备用来自己卖。那么,他的购物车里包含当当网80%的书。假设当当网有100万本书,也就是说他买了80万本书。根据余弦相似度算法,因为这样的一个用户,有80万本书两两之间就产生了相似度。
这个用户虽然买书,但是买这些书并非出于自己的兴趣,而且这些书覆盖了当当网图书的很多领域,所以这个用户对于他购买书的两两相似度贡献应该小于一个只买了几十本自己喜欢的书的文学青年。
因此对活跃的用户的行为,一般有两种处理方式
- 活跃用户行为不纳入计算商品相似度的数据集范围中;
- 活跃用户行为小于相对不活跃用户行为对商品相似度的贡献,活跃用户对商品的评价降权,一种降权的算法如下
$$w^{u} = \frac{log2.0}{log(3.0+count_{U}(I))}.$$
其中,$count_{U}(I)$ 表示用户 $U$ 有过行为的商品个数。
活动商品、虚拟商品
- 活动商品
电商一般会搞拉新等活动,免费给用户赠送商品,这种活动商品是用户非自己兴趣购买的商品,这种ORDER行为对商品相似度的贡献是噪音,应当忽略。
- 虚拟商品
电商一般会有虚拟商品,比如充话费,用户下单购买话费,这种特殊的虚拟商品也不能反映用户的兴趣,应当忽略对这种虚拟商品的行为。
用户行为的权重、主动性、频率
- 用户行为权重
在上面 寻找相似商品 中对用户的点击(CLICK)、收藏(FAV)、加购(CART)和下单(ORDER)行为分别赋予不同的权重分数,代表用户对有过行为的商品的态度和偏好
$score=(s_{click}, s_{fav}, s_{cart}, s_{order}).$
给予不同行为合适的权重评分,能够更好的刻画商品之间的相似度。
- 用户行为主动性
用户逛电商APP时,如果逛特卖的电商APP,APP首页会有推送商品首先供用户浏览点击,如果用户想要购买某商品,一般会在商品分类里面去查找,或者通过搜索直接查找。
对比用户对首页展示的商品的行为,用户在分类和搜索时对商品行为更能体现用户的态度和偏好。因此用户对出现在分类和搜索中的商品的评分应该更高。
- 用户行为的频率
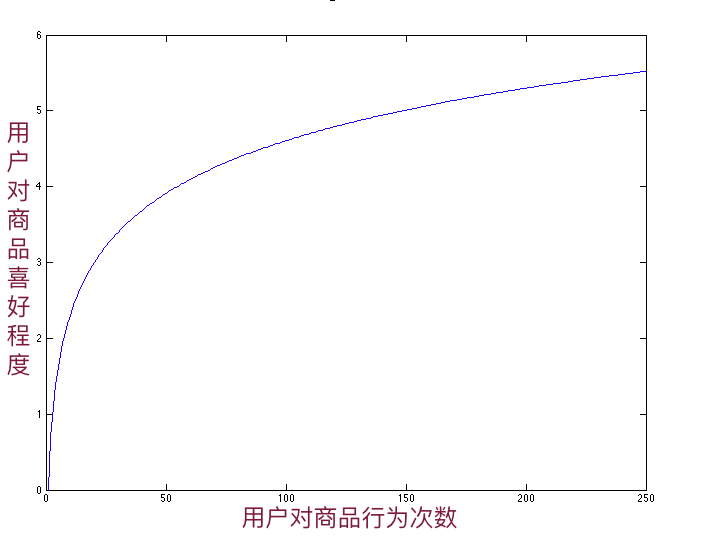
用户对喜欢的商品,一般行为次数会比较多。分析用户 $U$ 对商品 $I$ 的行为频率,如果行为次数从0次增长到10次,代表用户对这个商品喜好越来越强;但是如果行为次数已经到了 200 次,次数再增加10次,显然没有从0次直接增加到10次时喜好程度增加多。
如何去刻画用户这种随着行为频率的变化,对商品的喜好程度变化呢,这里我们采用了 $log$ 函数进行了平滑。
时间衰减
个性化推荐商品,推荐出来的商品要符合用户最近的兴趣,而用户最近的行为相比历史行为更能够反应用户最近的兴趣。因此,在考虑用户行为评分时,最近的行为的评分应当比历史行为的评分要高些,即从最近一直往前,用户行为的评分应当随着时间衰减。
$score_{click, n}(U, I)=\alpha^{n}\cdot score_{click}(U, I).$
其中,$score_{click, n}(U, I)$ 代表距离今天往前数第 $n$ 天用户 $U$ 对商品 $I$ 的CLICK行为评分,$score_{click}(U, I)$ 代表CLICK行为的评分,$\alpha$ 是衰减系数,例如 0.618。则昨天的CLICK行为评分为
$score_{click, 1}(U, I)=\alpha^{1}\cdot score_{click}(U, I).$
多样性
在预测出用户喜欢的Top N个商品后,就可以按照喜好程度降序推荐给商品列表。如果列表中连续都是同一个类目的商品,比如列表中连续4个都是手机,这样的用户体验非常不好,资源位浪费。
因此在推荐给用户前,可以按照类目对推荐的商品列表进行类目打散,展现多样性的商品。
工程实现优化
当算法输入的样本数据量较大时,算法的运行时间可以依靠工程技巧进行降低,下面介绍一些在基于Spark预测用户喜欢商品时的一些工程技巧。
序列化和反序列化
输入样本中,用户和商品可能以不同的字符表示,比如用户ID可能是32位的字符串,如 5aec08bc4c953feb440896804535a46d ,而商品可能是数字,如 10057309。样本数据格式统一整齐,在内存中计算时能够加快计算速度。
因此,可以考虑对用户ID和商品ID进行序列化,映射到同一数据类型,比如长整型。通过长整型计算完后再反序列化映射到用户ID和商品ID原有的类型。
数据倾斜
在shuffle类型的算子,如join操作,在计算过程中会将相同的key数据分配的同一个partition,当key相关的数据条数分布不均时,部分partition中的key的样本条数是其他partition数据条数的10倍甚至更多,这样数据条数多的partition对应的计算任务task就会花费大量的时间进行计算,拉长算法的执行时间。
对这种key下样本条数分布严重不均匀的情况,可以考虑用随机前缀和扩容RDD进行join等策略。
广播变量
在使用Spark进行计算时,会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时就应该使用Spark的广播(Broadcast)功能来提升性能。
map-side预聚合
所谓的map-side预聚合,说的是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。通常来说,在可能的情况下,建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
Top40 VS. Top200
在预测用户感兴趣商品时,先寻找每个商品相似的商品,再寻找用户喜欢的商品。每个商品相似的商品的数据集,作为寻找用户喜欢的商品的输入数据集。
选择每个商品相似商品的个数不同,会影响最终用户喜欢商品的集合,以及寻找用户喜欢商品的计算时间。在实验中发现,选择Top40的相似商品和选择Top200的相似商品,在最终寻找到用户喜欢商品的的集合中,按照喜好程度排序的Top40的商品基本一致,但寻找用户喜欢商品的计算时间有效减少了。
因此,选择较合适相似商品的个数,能够平衡最终用户喜欢商品集合的效果,和寻找用户喜欢商品的计算时间。
模型问题
用户冷启动
基于物品的协同过滤算法寻找用户喜欢的商品,需要依赖用户有历史行为。如果第一次逛APP,缺失用户的历史行为,就无法得到用户感兴趣的商品集合,即用户冷启动问题。
对于用户冷启动问题,可以如下方式寻找用户可能感兴趣的商品
- 基于用户实时的CLICK、FAV、CART和ORDER行为,寻找这些行为对应的商品的相似商品推荐给用户;
- 基于用户的特征,如性别、地域、手机操作系统(IOS/Android)、手机品牌(如vivo、apple、xiaomi),统计不同特征下的热销商品,组合推荐给用户。
新商品
对于用户行为稀少的新商品,在上述基于物品的协同过滤算法中被过滤掉了,因此,在最终的推荐结果中不会出现这些商品。
对于新商品,可以根据用户对商品品牌、类目等偏好,适量的插入到推荐列表中,增加这些商品的曝光次数,获取更多的用户的行为。
总结
本文讲述了基于商品的协同过滤算法进行商品的个性化推荐,首先介绍了基于商品的协同过滤算法,接着分寻找相似商品和寻找用户喜欢商品介绍了个性化推荐的过程,然后从基于业务背景优化和工程实现优化两方面介绍了算法优化迭代的思路,最后分析了这种算法存在的两个问题,用户冷启动问题和新商品问题。
参考资料
- 项亮,《推荐系统实践》,人民邮电出版社
- Spark性能优化指南——基础篇
- 余弦距离、欧氏距离和杰卡德相似性度量的对比分析
- Spark对数据倾斜的八种处理方法
