基于Topic Model的商品排序
问题背景
在 基于朴素贝叶斯分类器的商品排序 中讨论了通过朴素贝叶斯分类器对商品排序,同样的问题背景,本文讨论基于无监督的Topic Model对商品排序,即如何对 200 多个商品排序,使得用户感兴趣的商品排在前面,提高99模块的点击率?
Topic Model
两种Topic Model模型
当我们看到一篇文章后,有时会推测这篇文章是如何生成的。我们可能会认为作者先确定这篇文章的几个主题,然后围绕这几个主题遣词造句,表达成文。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
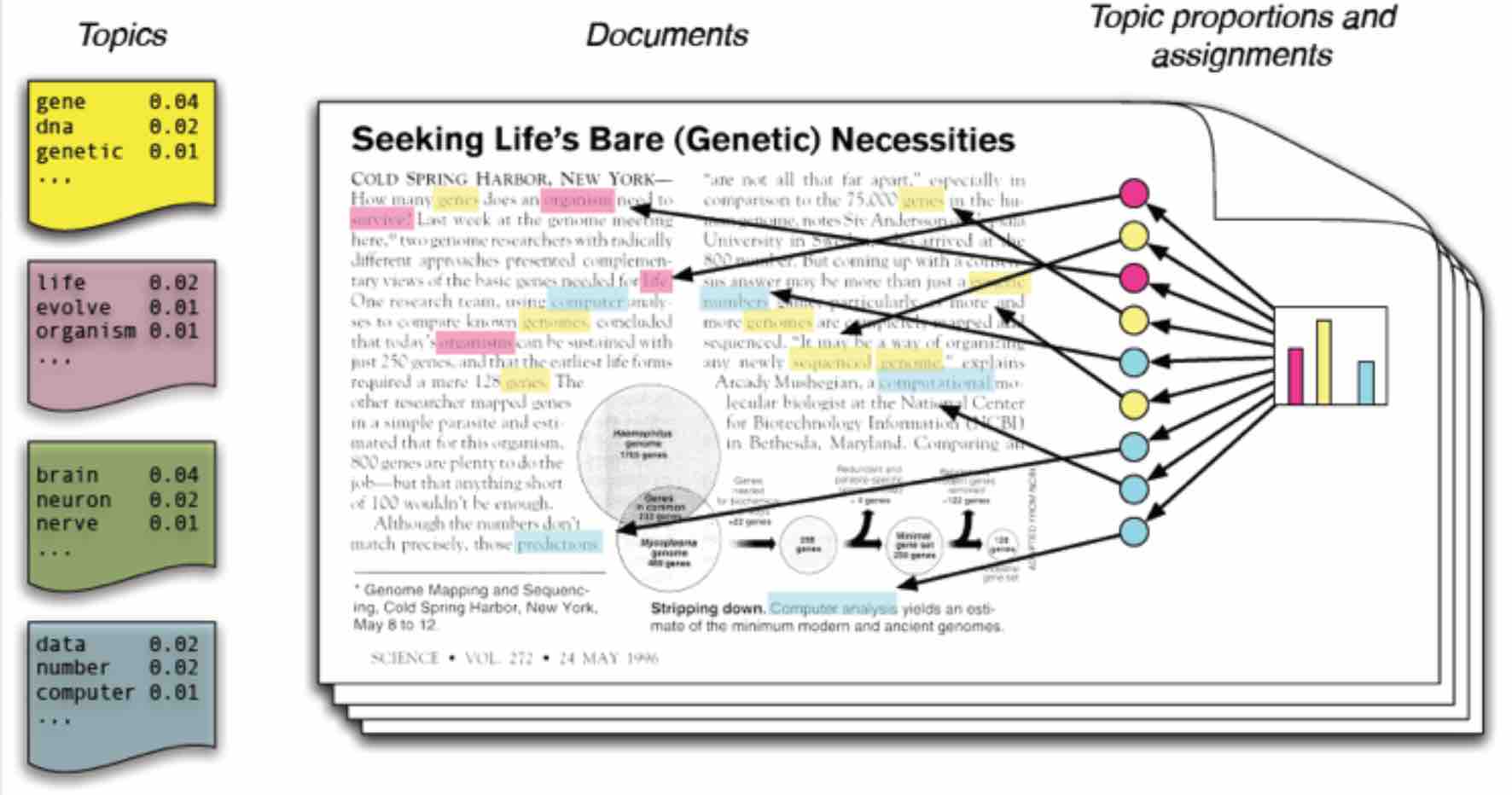
那么,能不能分析各篇文章分别都写了哪些主题,且文章中各个主题出现的概率大小(主题分布)是多少?
要解决上述问题,可以使用Topic Model模型。Topic Model 模型主要有pLSA 和 LDA。
- pLSA,即 Probabilistic Latent Semantic Analysis,1999年由 Hoffmn提出。pLSA 假设文章中有多个主题,并且给出每个主题的概率,以及每个主题下出现的词的概率,pLSA 假设文章中的各个主题概率是一定的,每个主题下出现的词的概率也是一定的;
- LDA,即 Latent Dirichlet Allocation,2003年由 Blei David M.、Ng, Andrew Y.、Jordan 提出。LDA 假设文章中有多个主题,并且给出每个主题的概率,以及每个主题下出现的词的概率,和 pLSA 不同的是,LDA 认为文章中每个主题的概率不是一定的,每个主题的概率满足一定的概率分布,并且每个主题下出现的词的概率也不是一定的,每个词在当前主题下出现的概率满足一定的概率分布。
本文主要讲述 $pLSA$,为说清楚 $pLSA$,先简要介绍下 文本建模。
文本建模
我们日常生活中总会产生大量的文本,如果每一个文本存储为一篇文档,那每篇文档从人的观察来说就是有序的词序列。为了方便描述,首先定义一些变量
- $w$ 表示词,$V$ 表示词典中单词的个数;
- $z$ 表示主题,$K$ 是主题的个数;
- $d=(w_{1}, w_{2}, \cdots, w_{N})$ 表示文档,其中 $N$ 表示一个文档中的词个数;
- $s=(d_{1}, d_{2}, \cdots, d_{M})$ 表示语料库,其中 $M$ 表示语料库中的文档个数。
那么,包含 $m$ 篇文档的语料库可以表示如下
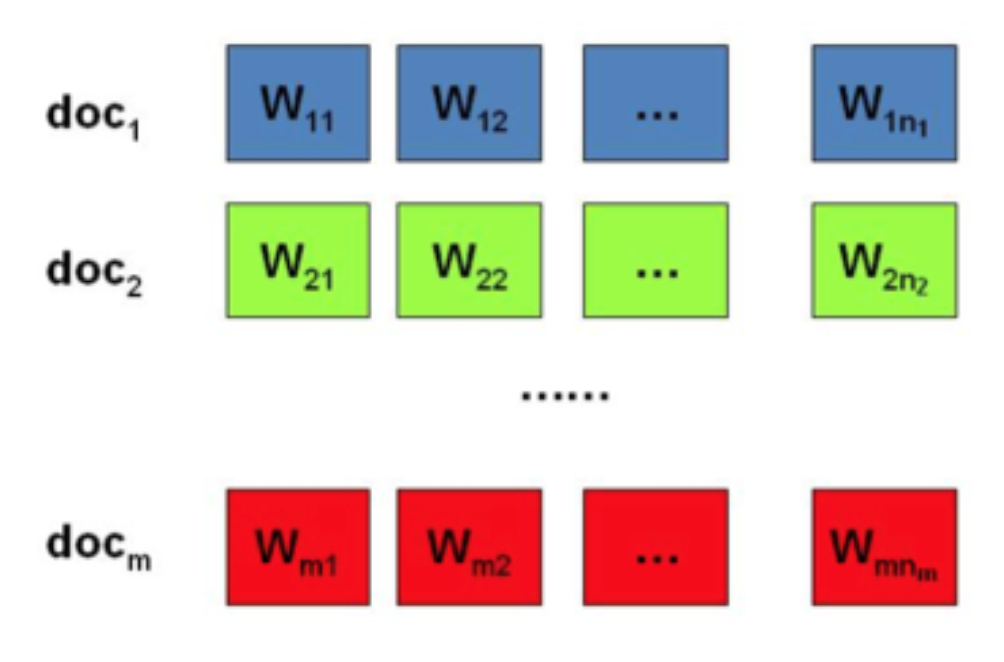
在 Unigram Model 中,我们假设文档之间是独立可交换的,而文档中的词也是独立可交换的,所以一篇文档相当于一个袋子,里面装了一些词,而词的顺序信息就无关紧要了,这样的模型也称为 词袋模型(Bag-of-words) 。
基于词袋模型,含有 $N$ 个词的文档的生成概率课表示为
$$\begin{eqnarray}
p(d) & = & p(w_{1}, w_{2}, \cdots, w_{N}) \\
{} & = & p(w_{1}) \cdot p(w_{1}) \cdot p(w_{2}), \cdots, p(w_{N}) \\
{} & = & \prod_{i=1}^{N}P(w_{i})
\end{eqnarray}$$
其中,$p(d)$ 表示生成文档 $d$ 的概率,而 $P(w_{i})$ 表示从词典中生成词 $w_{i}$ 的概率。用图模型表示为
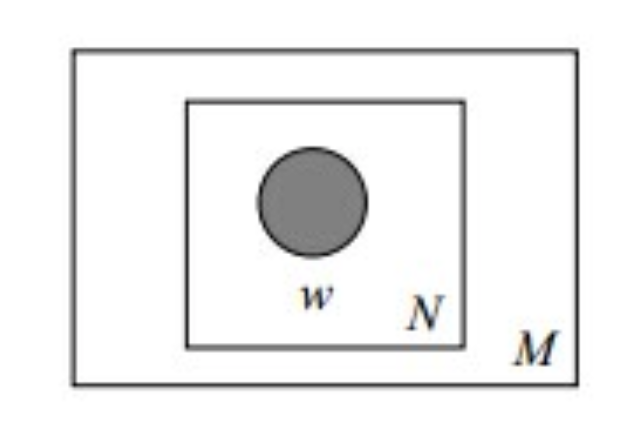
其中,被涂色的 $w$ 为观察量,$N$ 表示一篇文档中的单词数量,$M$ 表示语料库中的文档数。
pLSA
我们在构思文章时,往往是先确定要写哪几个主题,比如构思一篇NLP相关的文章,可能40%篇幅谈语言学,30%篇幅谈概率论,30%篇幅谈计算机:
- 语言学,容易想到的词汇:语法、句子、语法分析…
- 概率论,容易想到的词汇:概率、模型、均值…
- 计算机,容易想到的词汇:CPU、内存、二进制…
一篇文章通常由多个主题构成,而每个主题大概可以用与该主题相关的频率最高的词来描述。
按照 pLSA 模型的文档生成过程,我们并未关注词与词之间的顺序,形式化过程
- $P(d_{i})$,海量文档中某篇文档被选中的概率;
- $P(w_{j}|d_{i})$,词 $w_{j}$ 在给定的文档 $d_{i}$ 中出现的概率;
- $P(z_{k}|d_{i})$,具体某个主题 $z_{k}$ 在给定文档 $d_{i}$ 下出现的概率;
- $P(w_{j}|z_{k})$,具体某个词 $w_{j}$ 在给定主题 $z_{k}$ 下出现的概率;
根据上述1、3 和 4 的概率,可按照如下步骤得到 “文档-词项” 的生成模型:
- 按照概率 $P(d_{i})$ 选择一篇文档 $d_{i}$;
- 选定文档 $d_{i}$ 之后,从主题分布中按照概率 $P(z_{k}|d_{i})$ 选择一个隐含的主题类别 $z_{k}$;
- 选定 $z_{k}$ 之后,从词分布中按照概率 $P(w_{j}|z_{k})$ 选择一个词 $w_{j}$.
根据以上过程,文档 $d_{i}$ 中词 $w_{j}$ 的生成概率
$$P(w_{j}|d_{i})=\sum_{k=1}^{K}P(w_{j}|z_{k})\cdot P(z_{k}|d_{i}).$$
文档中每个词的生成概率
$$\begin{eqnarray}
P(d_{i}, w_{j}) & = & P(d_{i})\cdot P(w_{j}|d_{i}) \\
{} & = & P(d_{i})\cdot \sum_{k=1}^{K}[P(w_{j}|z_{k})\cdot P(z_{k}|d_{i})]
\end{eqnarray}$$
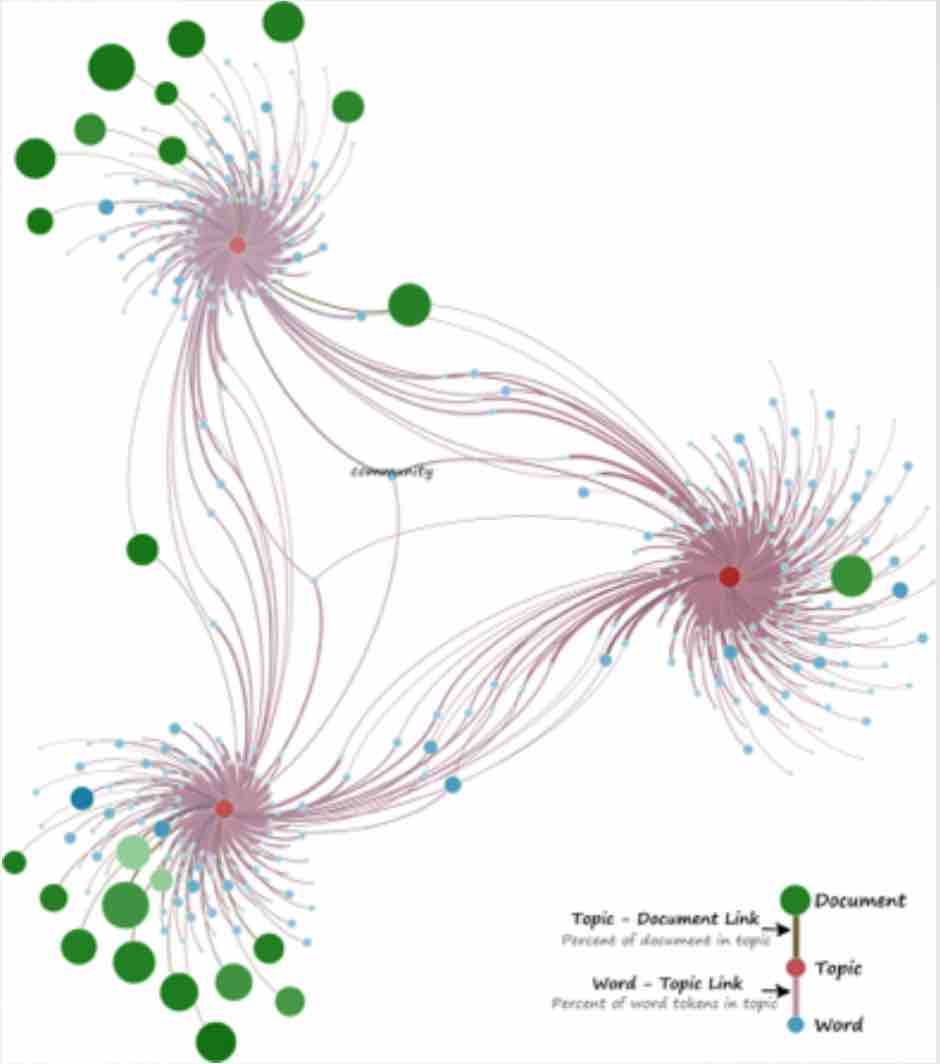
pLSA 的图模型如下
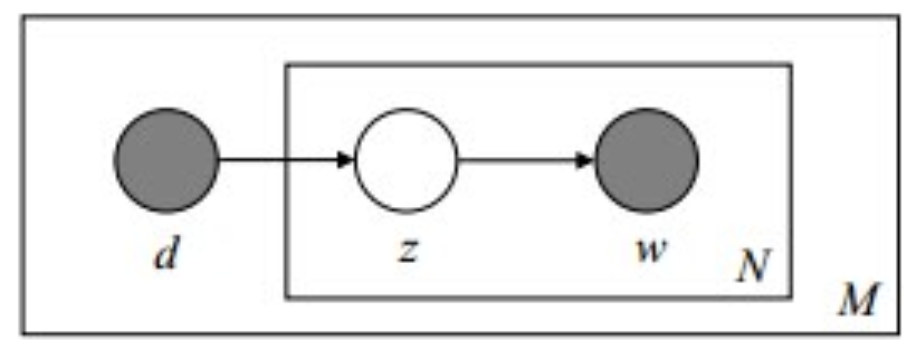
由于 $P(w_{j}|d_{i})$ 可观测到,$P(d_{i})$ 可事先计算求出,因此,$P(w_{j}|z_{k})$ 和 $P(z_{k}|d_{i})$ 是需要估计的参数,通过 $EM算法$ 估计。
基于Topic Model的商品排序
用户在逛APP时,每个用户都有自己的兴趣,并会对自己感兴趣的商品,进行点击(CLICK)、收藏(FAV)、加购(CART)或者下单(ORDER)。这里做如下假设
- 每一个商品是都是一个词 $w$,$V$ 表示商品的个数;
- $z$ 表示用户的兴趣,$K$ 是用户兴趣的个数;
- $d=(w_{1}, w_{2}, \cdots, w_{N})$ 表示用户有过行为的商品,其中 $N$ 表示用户有过行为的商品的个数;
- $s=(d_{1}, d_{2}, \cdots, d_{M})$ 表示访问过APP的用户集合,其中 $M$ 表示集合中用户的个数。
按上述假设,每个商品类比为词,每个用户有过上述4种行为的商品集合作为文档,所有用户有过行为商品集合作为语料库。借鉴 pLSA 的思想,可以应用到电商场景中。
已知每个用户有过行为的商品集合,需要估计用户有哪些兴趣,并且每个兴趣下代表性的商品和商品的概率分布。即已知用户 $d_{i}$,和用户有过行为的商品集合 $d=(w_{1}, w_{2}, \cdots, w_{N})$,需要估计用户的兴趣分布 $P(z_{k}|d_{i})$ 和每个兴趣下的商品概率分布 $P(w_{j}|z_{k})$。
本文开始的问题背景中,在9块9模块中,如何对 200 多个商品排序,使得用户感兴趣的商品排在前面,提高99模块的点击率?
即对于一个用户 $d_{i}$ 和一个商品 $w_{j}$,需要知道用户 $d_{i}$ 对这个商品 $w_{j}$ 感兴趣概率是多少。如果知道用户的兴趣分布 $P(z_{k}|d_{i})$,以及每个兴趣下的商品概率分布 $P(w_{j}|z_{k})$,就可以知道用户对这个商品感兴趣的概率,即
$$\begin{eqnarray}
P(d_{i}, w_{j}|z_{k}) = \sum_{k=1}^{K}[P(w_{j}|z_{k})\cdot P(z_{k}|d_{i})]
\end{eqnarray}$$
电商场景的语料库构建
考虑到用户不同行为,对商品感兴趣程度强弱不同,从点击(CLICK)、收藏(FAV)、加购(CART)到下单(ORDER),用户的兴趣越来越强,因此,如果4种行为的权重为
$$W = (w_{click}, w_{fav}, w_{cart}, w_{order}).$$
并且4种行为对同一个商品的行为次数分别为
$$cnt = (cnt_{click}, cnt_{fav}, cnt_{cart}, cnt_{order})$$
则最终用户对商品的最终行为次数可以表示为
$$cnt_{d_{i}, w_{j}}=\sum_{b \in \{click, fav, cart, order\}}(w_{b}\cdot cnt_{b}).$$
考虑到不同行为表达用户对商品不同的感兴趣程度差异,则电商场景的语料库构建如下
$$
\left(
\begin{matrix}
(d_{1}, w_{11}, cnt_{1, 11}) & (d_{1}, w_{12}, cnt_{1, 12}) & \cdots & (d_{1}, w_{1n_{1}}, cnt_{1, 1n_{1}})\\
(d_{2}, w_{21}, cnt_{2, 21}) & (d_{2}, w_{22}, cnt_{1, 22}) & \cdots & (d_{2}, w_{2n_{2}}, cnt_{2, 2n_{2}})\\
\cdots & \cdots & \cdots & \cdots \\
(d_{m}, w_{m1}, cnt_{m, m1}) & (d_{m}, w_{m2}, cnt_{1, m2}) & \cdots & (d_{m}, w_{mn_{m}}, cnt_{m, mn_{m}})
\end{matrix}
\right)
$$
上面矩阵中,每一行表示用户有过行为的商品,及行为次数统计,类比于一篇文档;共 $m$ 个用户即代表语料库有 $m$ 篇文档。
基于以上语料库,可通过 EM算法 得到用户的兴趣分布 $P(z_{k}|d_{i})$,以及每个兴趣下的商品概率分布 $P(w_{j}|z_{k})$,再根据公式(6)就可以得到用户对任意商品的感兴趣概率。
总结
本文讲述了基于Topic Model中 pLSA 算法进行商品排序,解决在APP的9块9模块中,对 200 多个商品排序,使得用户感兴趣的商品排在前面,提高99模块的点击率的问题。借鉴 pLSA 的思想,通过将商品类比为词,用户有过行为的商品集合作为文档,所有用户有过行为商品集合作为语料库,分析用户的兴趣分布,以及每个兴趣下商品的概率分布,得到用户对任意商品的感兴趣概率。
参考资料
- Rickjin(靳志辉), 《LDA数学八卦》
- v_JULY_v, 通俗理解LDA主题模型
