浅谈MapReduce
MapReduce被提出,已有10年多,广泛应用于大数据领域,在21世纪这信息爆炸时代,有效地帮助无数多的攻城狮解决处理海量数据的困扰。
概述
在 OSDI 2004,Google 的两名科学家 Jeffrefy Dean 和 Sanjay Ghemawat 在一篇名为 MapReduce: Simplified Data Processing on Large Clusters 的 paper 中讲述了 MapReduce,该 paper 在写本文时已被引用高达 15542 次。本篇主要以该 paper 中对 MapReduce 的描述,以及自己的开发经验,简要谈一下对 MapReduce 的理解。
MapReduce是一个编程模型,用于处理海量数据,生成目标数据结果。MapReduce 将任务的计算过程划分为2个阶段: Map 阶段和 Reduce 阶段。计算过程中,在 Map 阶段,对业务逻辑的每一条 记录 作为输入,生成一组 <key, value> 对作为中间结果;接着,在 Reduce 阶段,将 Map 阶段中生成的一组 <key, value> 对中间结果进行合并,即对具有相同 key 的 value 进行合并,这里的合并可能是做聚合操作,也可能是进行排序等操作,然后将最终合并后的结果输出。让人欣喜的是,现实世界中的许多问题处理过程,都可以表达成这样的模型。
由于 MapReduce 模型非常简单,在使用 MapReduce 进行计算时,用户不需要考虑输入数据如何划分成多份,在大量的机器组成的集群上如何对程序的执行过程进行调度,不需要关心可能存在集群中有机器挂掉,以及集群中机器间通信问题,因此,即使没有任何并行和分布式开发经验的人,也可以快速掌握通过 MapReduce 处理海量数据的方法。
MapReduce编程模型
MapReduce模型计算过程以一组 <key, value> 对作为输入,输出一组 <key, value> 对。用户通过在程序中调用 MapReduce 库进行计算,MapReduce 库将计算过程表达成 Map 函数和 Reduce 函数。
在使用 MapReduce 时,用户需要自定义 Map 函数和 Reduce 函数;Map 函数的输入是一个 <key, value> 对,产生一组 <key, value> 对作为中间结果;而 Reduce 函数将中间结果中具有相同 key 的 value 做合并,并将最终合并后的结果输出。一般,一个 reduce 过程将会产生零个或者一个结果。
形式化表述 Map 函数和 Reduce 函数的过程如下:
1 | map (k1, v1) --> list(k2, v2) |
MapReduce应用CASE
WordCount
在一组文档中,需要统计所有文档中,每一个单词出现的频率。使用 MapReduce 进行统计时,伪代码可能是这样的:
1 | map(String key, String value): |
在 Map 函数中,对于文档中每一个单词,均生成 (word, 1) 这样的 key/value 对,传递给 Reduce 函数,在 Reduce 函数中,对每一个具有相同 word 的 key/value 对,累加值为1的 value,最终即可得到每一个单词在这组文档中出现的频率。
分布式Grep查找
运维经常会有这样的需求,即在大量非结构化的日志中,通过grep命令查找包含指定关键字的日志,并抽取出来。在使用 MapReduce 时, Map 函数以每一条日志作为输入,查找包含指定关键字的日志,然后传递给 Reduce 函数,而 Reduce 函数直接进行输出即可。Map 函数和 Reduce 函数均可以在集群中的多台机器上依次并行的计算。
MapReduce实现
MapReduce的执行过程可以通过下图进行描述:
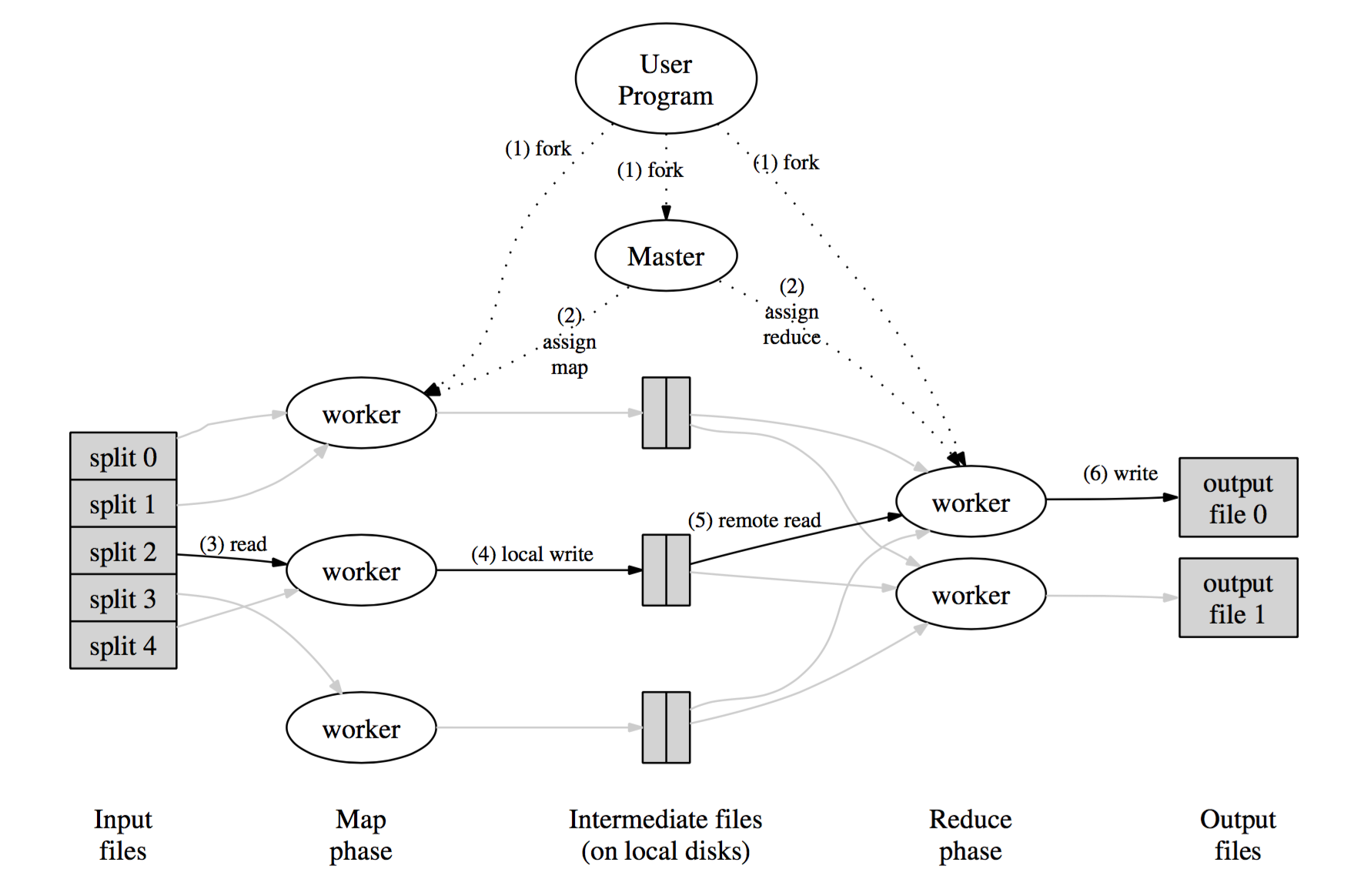
其中,Map 函数在集群中多台机器上,位于 HDFS 上的输入数据被划分为 M 份,输入的 M 份数据在可以在不同的机器上并行的处理。而 Reduce 函数亦位于集群中的多台机器上,通过一个分割函数,对产生的中间结果中的 key 划分成 R 份,这里的分隔函数类似 hash(key) mod R。用户可以自定义分隔函数,以及指定 R 值,即划分为多少份。
当用户调用执行 MapReduce 过程时,执行过程如上图中序号所示:
- 用户程序中的 MapReduce 库首先对数据文件分隔为
M份,每一份的大小可以是16MB至64MB,用户可以对划分的数据的大小进行配置。接着,程序将被拷贝多份至集群中多台机器上; - 众多拷贝程序中,有一个为
master,其他的为worker,并且,master将指派计算任务给worker。共有M个 map 任务和R个 reduce 任务将被指派。master将在集群中选择空闲的机器分配给一个 map 任务或者一个 reduce 任务。 - 被指派为 map 任务的
worker从对应的一份输入数据中读取内容,将输入数据转化为一组<key, value>对,并传递每一个键值对给用户实现的Map函数,产生新的<key, value>对作为中间结果缓存在内存中; - 缓存在内存中的键值对周期性的被写入本地硬盘,并通过
分隔函数划分为R个区域;这些在本地硬盘上缓存的中间结果的位置信息将会传递给master,并通过master转发给各被指派 reduce 任务的workder; - 当被指派 reduce 任务的
workder被master告知中间结果的位置信息后,reduce 任务的workder将会通过RPC读取位于 map 任务的worker的机器上的中间结果数据。当 reduce 任务的workder读取了所有的中间结果,将会按照key对中间结果进行排序,将具有相同key的键值对分组在一起。如果中间数据太大不能在内存中存储,外部排序将会被采用; - 被指派 reduce 任务的
workder迭代排序的中间结果数据,将每一个独立的key,以及其对应的value集合传递给用户实现的Reduce函数,Reduce函数的输出结果将被添加到该 reduce 任务的最终输出文件中; - 当所有的 map 任务和 reduce 任务完成后,
master唤醒用户的程序,用户程序中对MapReduce的调用将结束,执行过程返回至用户程序中。
总结
本文简要介绍了 MapReduce 编程模型的思想,并简单描述了 MapReduce 的执行过程。在执行过程中,如何进行容错、负载均衡、是否对中间结果压缩、以何种格式进行压缩等问题并没有说明。
参考资料
- Jeffrey Dean , Sanjay Ghemawat, MapReduce: simplified data processing on large clusters, Proceedings of the 6th conference on Symposium on Opearting Systems Design & Implementation, p.10-10, December 06-08, 2004, San Francisco, CA
