Oozie简介
![]()
Oozie 是一个用于管理 Hadoop Job 的工作流调度平台。Oozie 可以将多个 Job 按照一定的逻辑顺序组合起来运行。Oozie 支持的 Hadoop Job 类型有 Map Reduce、Pig、Hive 和 Sqoop。另外,Oozie 支持的 Job 类型还有 Java、Streaming、Fs(Hadoop File System 操作)、Ssh、Shell、Email 和 DistCp。Oozie 在 Hadoop 生态系统中的位置如下图所示。
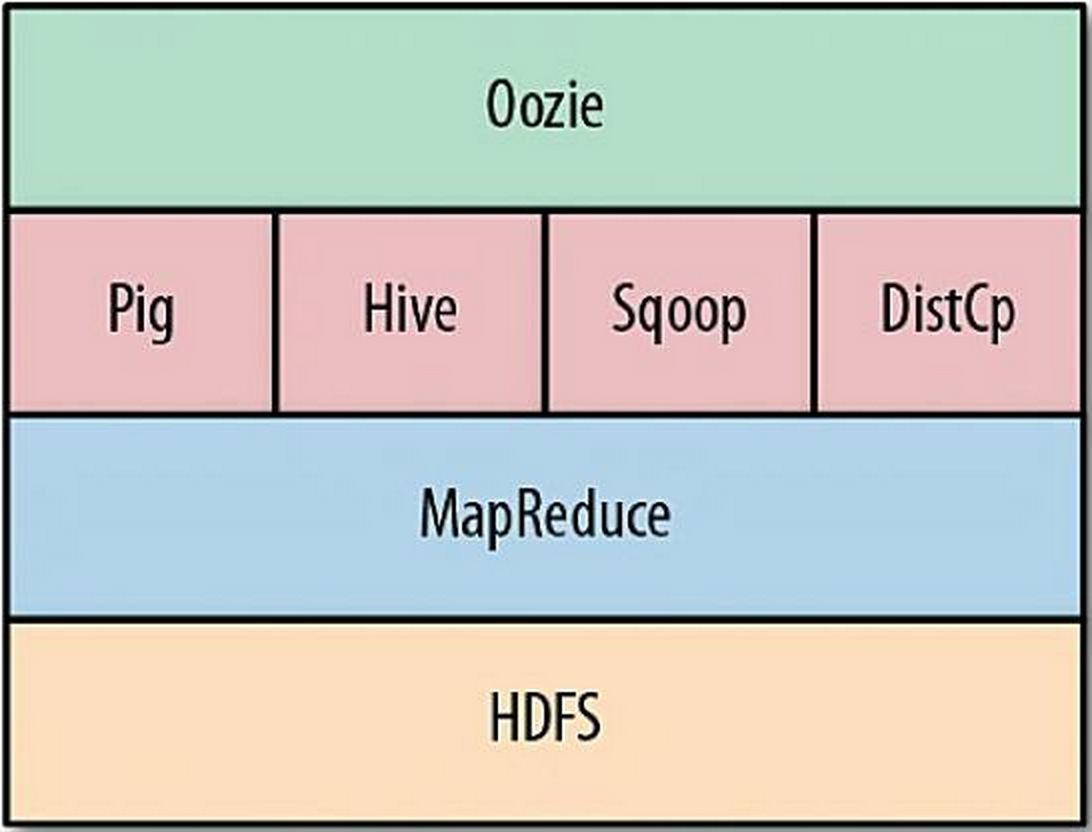
通过 Oozie 平台,用户可以在 Hadoop 集群上完成由多项子任务组合在一起的复杂数据计算过程。在 Oozie 中,共有 3 种类型的 Application:
- Workflow,即工作流,是一个有向无环图
(DAG,Directed Acyclic Graph),描述了需要执行的 Actions 序列; - Coordinator,即协调器,是依赖于时间或数据是否可用,周期性运行的 Oozie 工作流;
- Bundle,提供了一种打包多个协调器和工作流的方式,并可以管理这些 Tasks 的生命周期。
Oozie Workflow
工作流,顾名思义,即将需要执行的工作形成一个“流”,这里的工作即是一个 Job,可以是 Map Reduce、Pig、Hive、Sqoop、Java、Streaming、Fs(Hadoop File System 操作)、Ssh、Shell、Email 和 DistCp 中的任何一个,而“流”即是将至少一个 Job 根据相关的业务逻辑需求,按照顺序组织成一条“线”。Hadoop 在执行工作流时,将按照工作流中 Job 中的组织顺序依次执行。
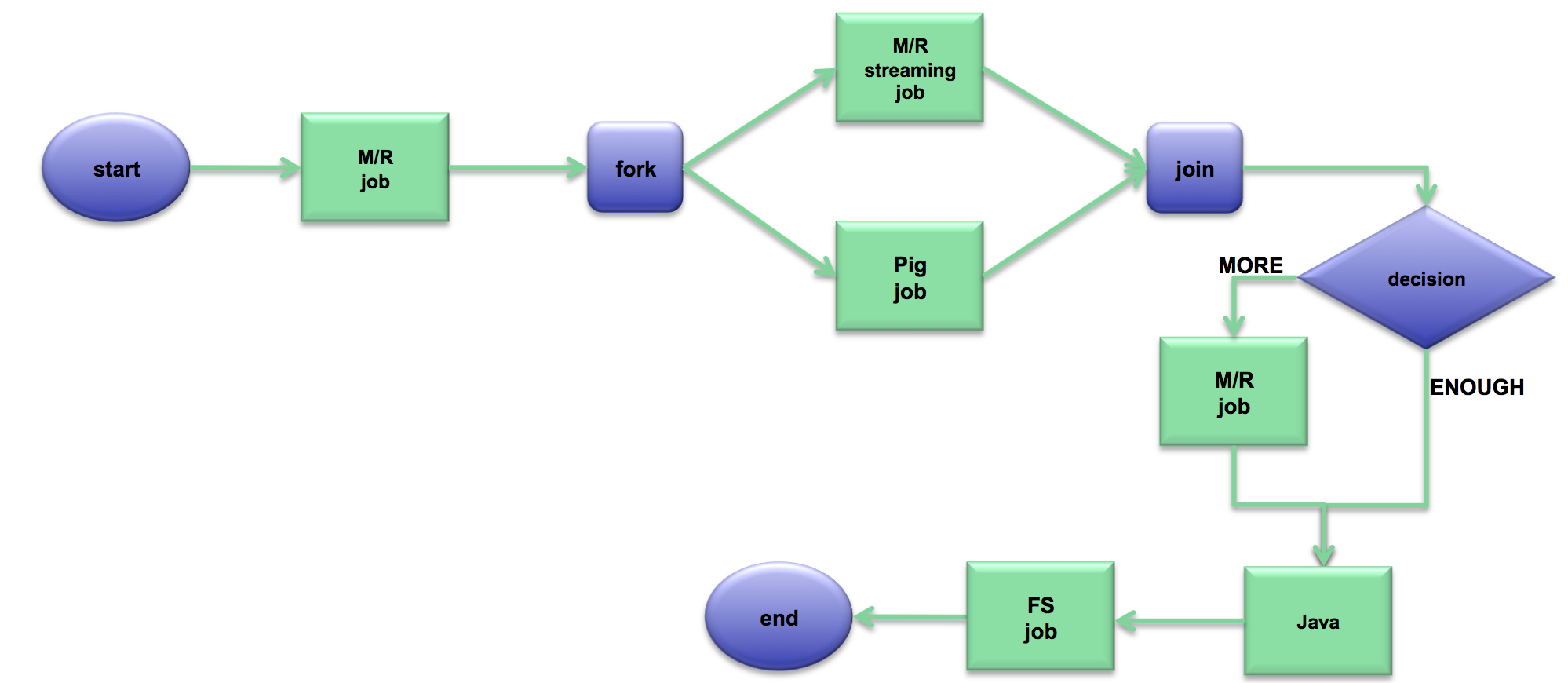
一个 Oozie 工作流是一个 DAG,其中的节点包括 Action 节点和 Control 节点。Action 节点即Oozie 支持的 Job 和 sub-workflows,而 Control 节点定义了工作流的执行路径,即设置工作流的开始与结束规则,以及通过 Decision、Fork 和 Join 节点控制工作流的执行路径。
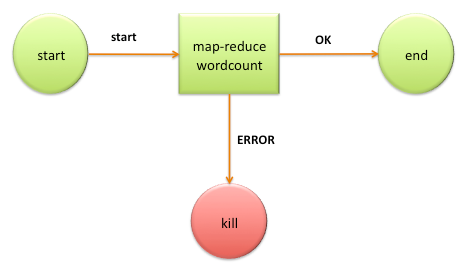
仅包含一个 Action 节点的统计单词个数的工作流示例图如下:
包含多个 Action 节点的工作流示例图如下:
那么,Oozie 是如何描述工作流呢?
Oozie 采用了 XML 对工作进行描述,即 hPDL (hadoop Process Definition Language)。上述统计单词个数的工作流的描述 workflow.xml 如下:
1 | <workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.1"> |
如上面 workflow.xml,有 3 个参数 jobTracker、nameNode 和 wcDir,在运行时,这些参数将会被实际的参数值取代。在 Hadoop 1.0 中,JobTracker(JT) 作为管理 MapReduce Jobs 的服务,但在 Hadoop 2.0 或 YARN 中被改进,在这里,可以将 YARN ResourceManager(RM) 作为新的 JT,在 jobTracker 传入 JT 或 RM。
每一个工作流都会有start、kill 和 end 控制节点,工作流从 start 节点开始执行,当遇到执行异常时,Oozie 会过渡到 error 元素,当执行成功后,Oozie 会过渡到 ok 元素。当过渡到 error 元素时,工作流将会转移到 kill 节点,杀死工作流,当过渡到 ok 元素时,工作流将会转移 end 节点。而中间的 action 节点即是实现业务逻辑的过程。如上例,action 节点中是一个 map-reduce 类型的 Job。
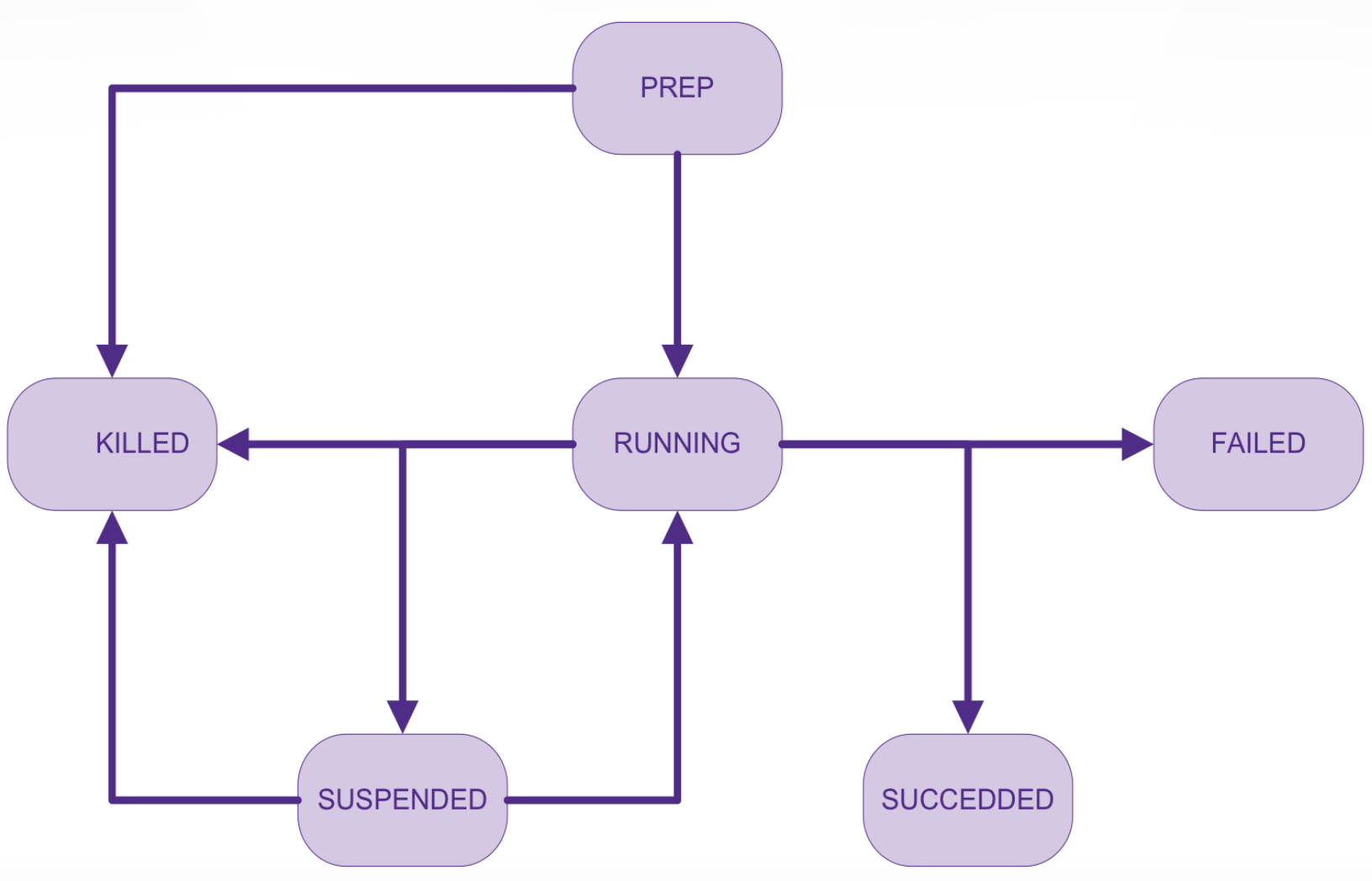
当创建一个工作流后,就会在 Oozie 中生成一个 Workflow Application,当提交运行 Application 时,就会生成一个 Workflow Job,即 Workflow Job 是 Workflow Application 的一个运行实例。每一个 Workflow Job 都有生命周期,周期中有这些状态:PREP、RUNNING、KILLED、SUSPENDED、SUCCEEDED 和 FAILED,状态之间转移关系如下图所示:
在统计单词的工作流应用中,工作流仅包含一个文件,即 workflow.xml。不过,在运行工作流之前,须得将必要的 jar 包和文件打包并部署到 HDFS 上。并且,workflow.xml 须位于应用的根目录。
1 | app/ |
另外,在运行工作流之前,需要创建 job.properties,指出工作流运行必要的参数和应用在 HDFS 上部署的位置:
1 | nameNode=hdfs://localhost:8020 |
Oozie Coordinator
Oozie 是用于管理 Hadoop Job 的工作流调度平台,工作流创建好之后,就需要 Coordinator 来进行调度了。Coordinator 进行调度依赖时间条件和数据是否可用。Coordinator 中几个关键的概念:
- Coordinator Action,即是一个 Workflow Job ,Job 在满足一系列条件后开始执行;
- Coordinator Application,定义了 Coordinator Action 的执行条件,包括 Coordinator Action 执行的时间频率,以及 Coordinator Action 需要被执行的开始时间和不再被执行的结束时间;
- Coordinator Job,即一个 Coordinator Application 的运行实例。
一个 Coordinator Application 的定义包括开始时间、结束时间、执行频率、输入数据、输出数据和被执行的工作流。一个 Coordinator Application 在开始时间起周期性的执行工作流,如下图所示。
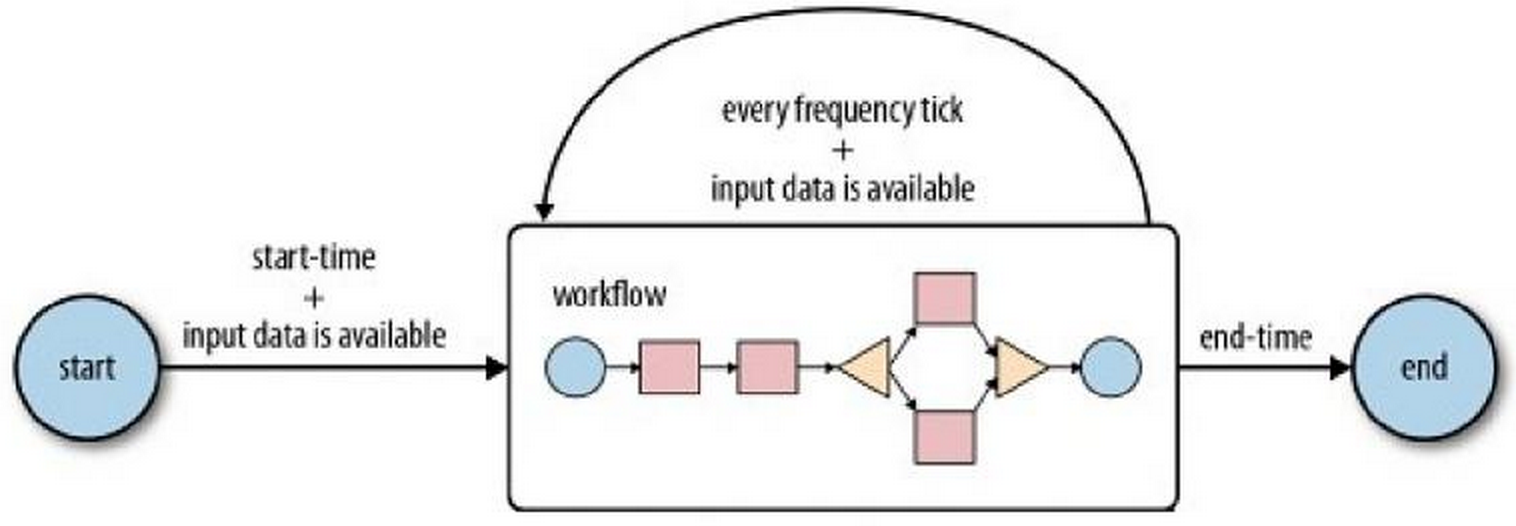
开始执行时,Coordinator Job 首先会检查是否输入数据能够获取到。当输入数据存在可用时,Workflow Job 处理输入数据,并产生对应的输出数据。如果输入数据不存在不可用时,Workflow Job 的执行过程推迟,直到输入数据可用。若结束时间条件满足时,Coordinator Job 不再执行。
Coordinator 的输入数据和输出数据通过数据集 dataset 定义。一个数据集实例即是一个数据集合的特定生成事件,通过一组唯一的 URI 表示。
语法:
1 | <dataset name="[NAME]" frequency="[FREQUENCY]" |
其中,name 即是数据集的名字,frequency 即数据集被周期性创建的频率, initial-instance 即数据集初次生成时间,timezone 即数据集的时间域,uri-template 是数据集的位置,dong-flag 标识数据集是否就绪可用。
例子:
1 | <dataset name="logs" frequency="${coord:days(1)}" |
其中,数据集名称为 logs,每天生成一次,位于hdfs://foo:8020/whlminds/logs/${YEAR}/${MONTH}/${DAY}路径下,并且当路径下出现文件 _SUCCESS 时表明数据就绪可被消费。
一个 Coordinator Application 的示例定义如下:
1 | <coordinator-app name="hello-coord" frequency="${coord:days(1)}" |
如上,在 dataset 定义好数据集后,Coordinator 通过 input-events 与 output-events 引用数据集,而 workflow 通过 EL 表达式 ${coord:dataIn('input')} 或 ${coord:dataOut('output')} 使用数据集。
Oozie Bundle
Bundle 是对 Oozie 的更高层的抽象,通过 Bundle 可以分批运行 Coordinator Application,用户可以在 Bundle 层面进行控制,如 start、stop、suspend、resume 和 rerun。
通过 Bundle ,用户可以将 Coordinator Application 串起来,形成数据管道。在一个 Bundle 定义中,各 Coordinator Application 不存在明确的依赖关系,但用户可以通过 Coordinator Application 之间的数据依赖创建一个明确的数据应用管道。
语法:
1 | <bundle-app name=[NAME] xmlns='uri:oozie:bundle:0.1'> |
其中,kick-off-time 是 Bundle 开始执行,提交 Coordinator Applications 的时间。
例子:
1 | <bundle-app name='APPNAME' xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance' xmlns='uri:oozie:bundle:0.1'> |
How Oozie Works
在实际应用中,通过 Oozie 进行调度时,Workflow、Coordinator 和 Bundle 之间呈层次关系,如下图所示。
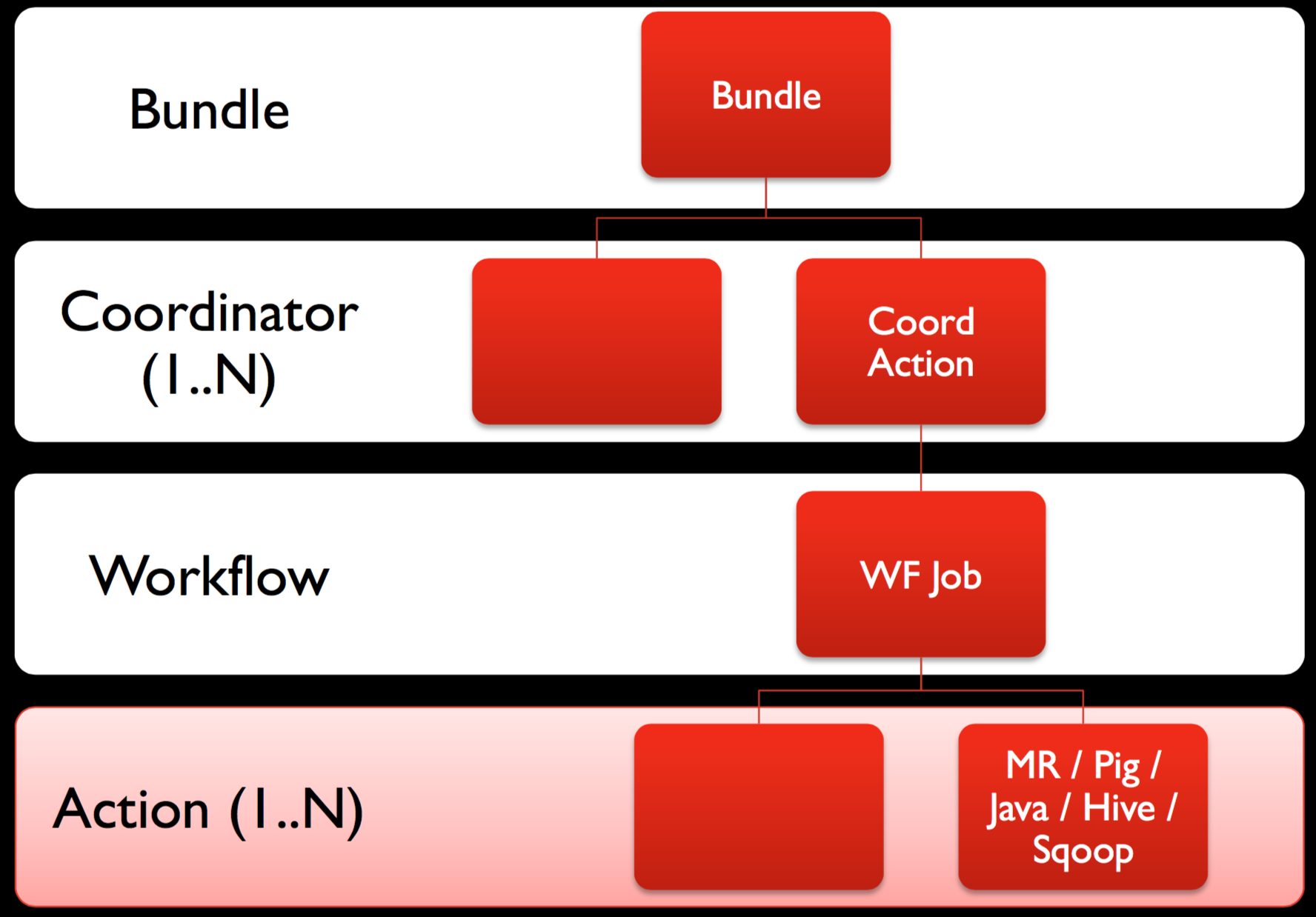
其中,一个 Workflow Application定义中至少有一个 Action,而一个 Coordinator Application 中仅有一个 Workflow Application,一个 Bundle 中至少有一个 Coordinator Application。
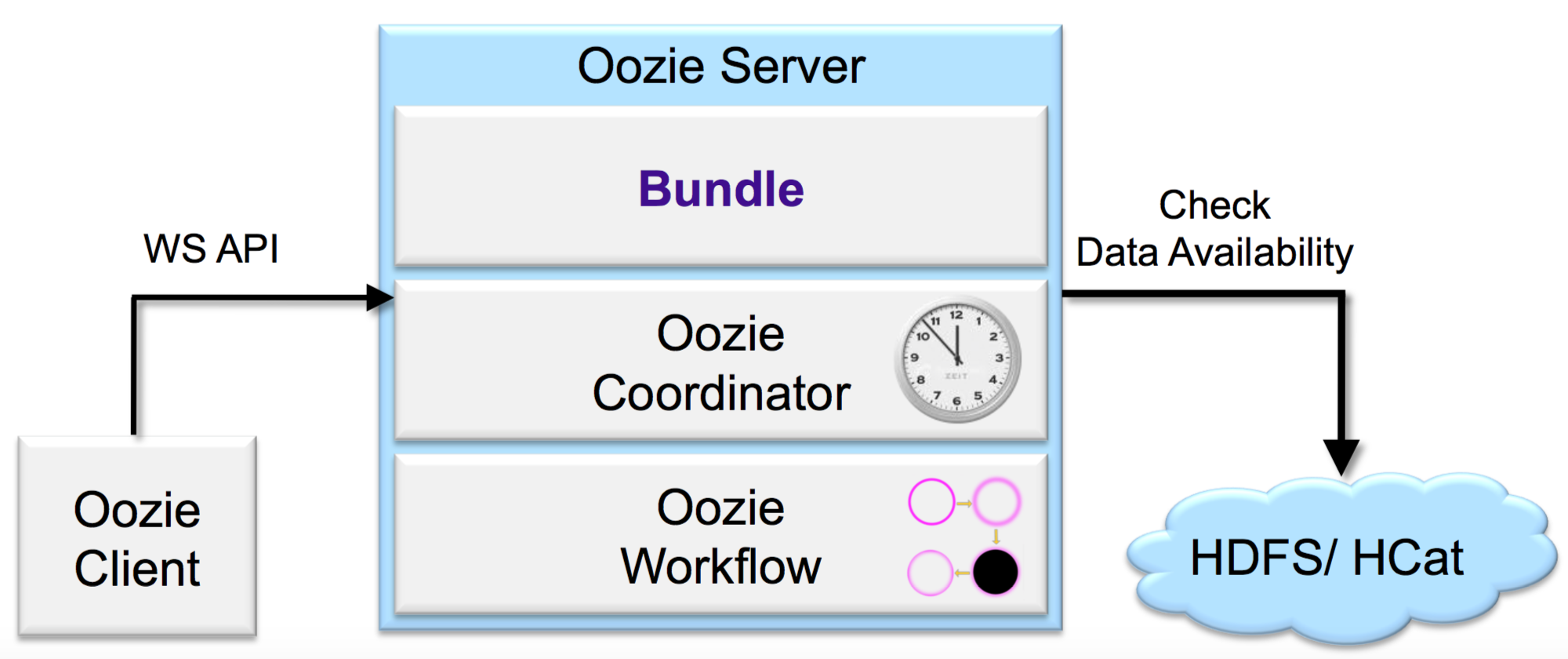
用户在使用 Oozie 进行调度时,通过 Oozie Client 提交任务给 Oozie Server,Oozie Server 负责管理任务的调度,并提交 Job 到 Hadoop 集群执行。
总结
本文尝试介绍 Oozie 中的核心组件概念,包括 Workflow、Coordinator 和 Bundle,并最后简要说明了用户使用 Oozie 提交任务调度过程。
Oozie 作为 Hadoop Job 的工作流调度平台,支持丰富的 Job 类型,提供了多种控制工作流的方式;同时,Oozie 拥有庞大的概念体系,要完全介绍清楚实属不易,关于 Oozie 中的参数化、安全等十分重要,但限于篇幅,并未说明。
本文中使用的图片均来自 slideshare.net 和 Apache Oozie: The Workflow Scheduler for Hadoop,感谢分享。
