Sqoop 简介
![]()
Sqoop 是一个在结构化、半结构化和非结构化数据源之间进行有效数据传输的工具。各种数据源中,例如,关系型数据库(RDBMS)中存储的数据都有数据模式(Schema),是结构化数据源;Cassandra 和 Hbase 是半结构化数据源;而 HDFS 是非结构化的数据源。
以 RDBMS 和 HDFS 之间数据传输为例,借助于 Sqoop,可以从 RDBMS 如 MySQL 或 Oracle 中导入数据到HDFS 中,通过 Hadoop 的 MapReduce 模型计算完之后,将结果导回 RDBMS。
根据被导入数据在数据库中定义的数据模式,Sqoop 将会自动完成整个过程中的大部分,其中,Sqoop 借助于 MapReduce 导入和导出数据,并提供容错和并行化操作。
Sqoop 有俩版本,即 Sqoop1 和 Sqoop2,最新的 Sqoop2 版本为 1.99.6,本文中介绍的 Sqoop 均为 Sqoop2。
Sqoop 安装
Sqoop 需要安装两部分,即 Server 端和 Client 端。Server 端可以安装在集群中一个节点上,该节点可以作为其他需要连接的 Client 端的接入点,并且,将作为一个 MapReduce 算子的请求客户端,因而,在提供有 Sqoop Server 的节点上须安装有 Hadoop。而 Sqoop Client 可以安装在集群中任意节点上。
具体安装细节请移步至 sqoop-installation。
Sqoop 如何工作
当用户在 Sqoop Client 端提交一个请求时, Sqoop Client 通过 REST 方式,以 JSON 格式仅向 Sqoop Server 发出请求。Sqoop Server 在收到请求之后,从数据源中抽取元数据(metadata),并向执行引擎授权执行请求,这里,执行引擎即 Hadoop 的 MapReduce 算子。在执行时,MapReduce 算子以并行化方式完成请求。整个请求过程如下图所示。
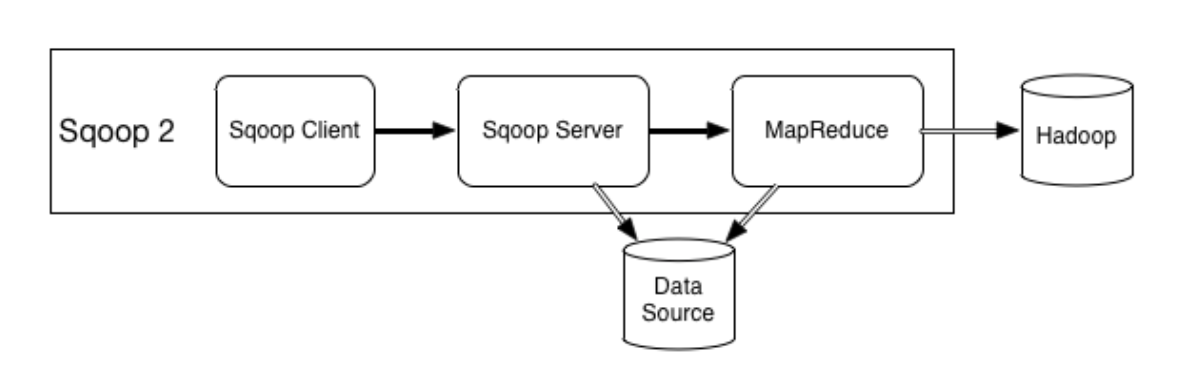
具体的,用户在使用 Sqoop 在不同数据源间导数据时,Sqoop Client 提供了 CLI 和浏览器两种方式提交请求,然后 Sqoop Server 收到请求后,授权 MapReduce 执行,如下图所示。
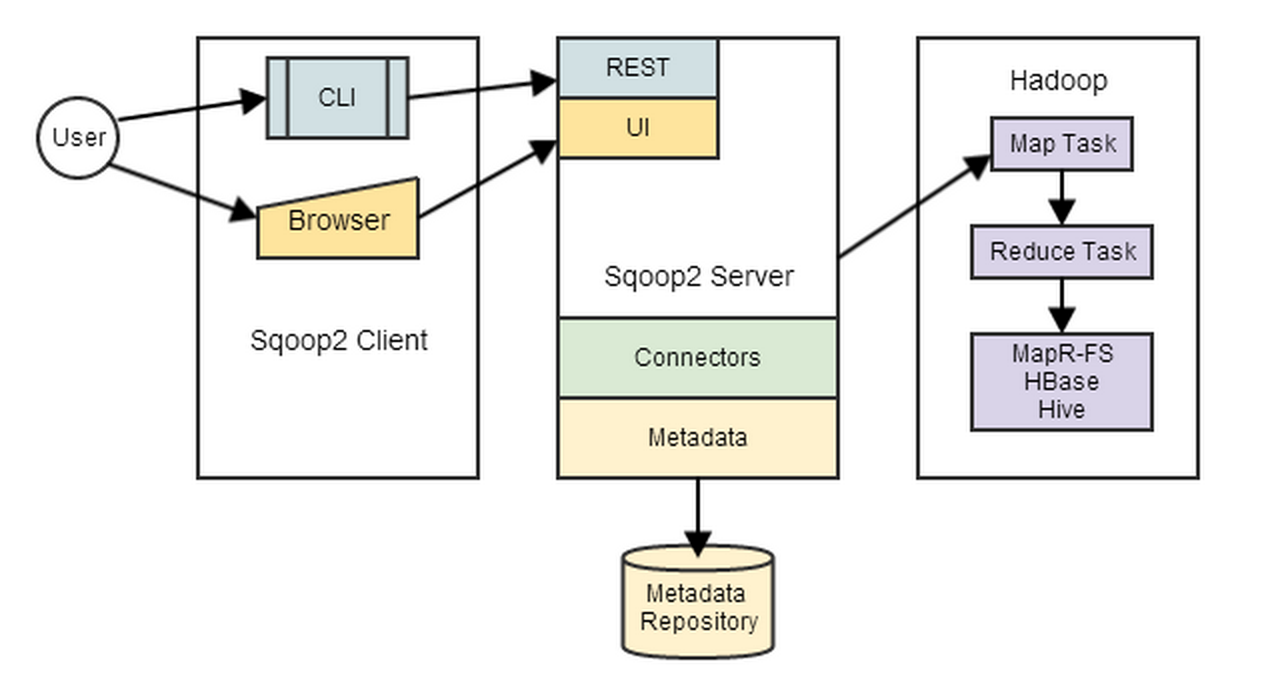
以利用 Sqoop 在关系型数据库和 HDFS 间传输数据为例。其中,导入过程的输入是一个数据库表,Sqoop 将会从表中一行一行的读入到 HDFS,导入过程的输出是一组包含被导入表数据的文件。因为导入过程是并行的,所以将会产生多个输出文件。这些文件可以是文本文件,文件中每一行对应一条数据库表中的记录,记录中每个域之间通过逗号或 \t 分割,也可以是二进制的 Avro,或包含序列化的数据的序列化文件。
在对导入的记录使用 MapReduce 或 Hive 等计算完后,可以将计算结果导回关系型数据库。Sqoop 的导出过程将会并行的从 HDFS 中读取一组文本文件,解析为记录,并插入到数据库表中,供其他业务或用户使用。
其中,导入和导出的过程的许多方面都可以被个性化定制。用户可以控制数据库表中需要导入的具体行和列,也可以指定文件的格式、列的分隔符和导入到文件后需要过滤的字符(如 \r\n)。
Sqoop 将每一个请求定义为一个 Sqoop Job,每一个 Sqoop Job 的生命周期由 sqoop connector API 定义,即在数据的 Extract/Load 过程对应于 MapReduce 引擎的 Map/Reduce 过程。这部分将在 Sqoop2 Connector 中介绍。
Sqoop 例子
具体的,如何利用 Sqoop 进行导入数据呢,这里以从 MySQL 导入数据到 Amazon S3 为例。
数据库 thu 中表 student 定义如下。
1 | use thu |
将表 student 导入 Amazon S3 的存储桶 thu.whlminds.com 中的 Shell 脚本如下。
1 | #!/bin/bash |
如上例 Shell 脚本中,将 MySQL 数据库 thu 中表 student 导入 Amazon S3 的存储桶 thu.whlminds.com 中。其中,选择了表部分字段 id 、name 和 gender。
其中,$CONDITIONS 是在并行导入数据时分隔数据源的条件。即如果想并行的导入查询的结果,则每一个 Map 任务需要执行一个查询的拷贝,每一个拷贝中,根据 $CONDITIONS 不同,每一个 Map 任务导入的数据不同,每一个 Map 任务在执行时会将 $CONDITIONS 替换成一个唯一的条件表达式,同时,需要通过 --split-by 来指定根据哪一列数据将需要导入的数据源分割,供多个并行的Map 任务导入。
而 --hive-drop-import-delims 指定在导数据时丢弃字符串中的 \n,\r 和 \01 供 Hive 查询。
具体的,关于 Sqoop 的语法,请参考 SqoopUserGuide。
总结
从 Sqoop 是什么,到如何安装,再到 Sqoop 导入数据的原理,本篇博客给出了简要的说明,最后,通过一个简单的例子简要的说明如何利用 Sqoop 编写数据在 RDBMS 和 Hadoop 文件系统间导入数据。
关于每一个 Sqoop Job 如何具体的通过 sqoop connector API 导数据,将在Sqoop2 Connector 中介绍。
